운영체제 관련 책들 중 공룡책으로 유명한 Operating System Concepts 책을 정리하고자 합니다.
현재 정리하고자 하는 책은 10th edition이며 책에 나와있는 그림을 포함하고 있습니다.
Operating System Concepts - 10th edition
www.os-book.com
Opearting System Services

운영체제는 위 그림과 같이 구성되어있으며, 사용자에게 다양한 기능들을 제공합니다.
흔히 사용자들은 user interface인 GUI, touch screen, command line을 통해 서비스를 이용하며, 운영체제가 제공하는 서비스들에 직접 접근하여 사용하지 않고, system call을 통해 해당되는 서비스를 요청합니다.
이러한 과정들을 하나씩 알아가봅시다.
User and Operating System Interface
Linux, Windows, MacOS 등 대부분의 운영체제가 Command interprerter를 가지고 있으며, 처음 유저가 로그인할 때 혹은 init 프로세스가 실행될 때, Command interprerter가 실행됩니다. 흔히 Command interpreter는 Shell (셸)로 알려져 있으며 다양한 명령어들을 해석하여 실행합니다.
Command interpreter의 주된 기능은 유저가 입력하는 명령어를 읽고 실행하는 것입니다.
UNIX 명령어 중 파일 삭제를 예시로 들어봅시다.
rm file.txt
rm 은 파일을 삭제하는 명령으로 file.txt 라는 파일을 삭제하는 명령을 입력한 것입니다. 위 명령을 실행하게 되면, rm이라는 파일을 찾아 파일을 메모리에 적재하고 파라미터로 넘긴 file.txt 파일을 삭제하게 됩니다.
유저는 위와 같이 Command-line interface를 사용하기도 하지만, 주로 GUI (Graphic User Interface)를 많이 사용합니다. 예를 들어, 윈도우에서 특정 폴더에 존재하는 파일을 지우려고 할 때, 폴더를 열어서 해당 파일에 마우스 우측 클릭을 하게 되면 뜨는 창의 목록들 중에 삭제를 클릭하여 파일을 삭제하곤 합니다.
이때, 유저에게 보여지는 윈도우 창과 마우스 등이 모두 GUI를 통해 볼 수 있게 되는 것입니다.
그럼, "굳이 Command-line interface를 사용하지 않고 GUI로 제공되는 것들만 사용하면 되는 것 아닌가?"라는 의문이 드실 수 있습니다. 하지만, 같은 일을 반복해야 할 때, Command-line interface를 사용하면 더 쉽게 처리할 수 있습니다. 리눅스와 유닉스 운영체제의 경우, Shell Script를 작성하여 자동화를 통해 같은 일을 처리하곤 합니다.
System Calls
시스템 콜은 운영체제에서 제공하는 서비스들을 사용할 수 있게 해주는 인터페이스 입니다.
시스템 콜은 Process Control, File management, Device management, Information maintenance, Communications, Protection으로 총 6가지 유형에서 활용됩니다.
예를 들어, 파일을 복사 생성을 위해 아래와 같은 명령을 입력하였을 경우 어떤 일이 발생하는지 알아봅시다.
cp in.txt out.txtin.txt 파일에 있는 내용을 out.txt에 복사하는 명령입니다. rm 명령어와 동일하게 cp 파일을 찾아 실행하게 되고 파일이 존재하는지 확인한 후 있을 경우 in.txt 파일을 열고 out.txt 파일이 존재하는지 확인한 후, 없을 경우 out.txt 파일을 생성하고 in.txt 파일에 내용을 out.txt에 쓰는 작업을 하게 됩니다.
이러한 작업을 수행하기 위해서는 시스템 콜(system call)이 요구됩니다. 하지만, 개발자가 직접 시스템 콜을 커널에게 전달하는 게 아니라 API (Application Programming Interface)를 통해 시스템 콜을 발생시키게 됩니다.
조금 더 구체적으로 다뤄보면, C 프로그램에서 exit(1) 함수를 호출했다고 가정합시다.
User Space에서 eax register에 system call number를 저장한 후, system call 요청을 위해 프로그램은 software interrupt를 트리거하는 special instruction을 실행합니다. 이후, Trap이 발생하여 제어권을 커널로 이전하고 System Call Handler를 실행하게 됩니다.
System Call Handler는 eax register와 index를 포함하는 trap frame으로부터 system call number를 로드하고 system call table에 해당되는 entry를 발생시키고, User Space에서 실행된 프로그램의 인자 값을 읽어와 exit() 함수를 실행하게 되는 것입니다. 실행된 결과는 Kernel Space에서 User Space 프로그램으로 Return합니다.
이와 같이, 복잡한 과정을 거쳐 함수를 실행하게 됩니다. 그럼, 함수의 파라미터 값들은 어떻게 전달될까요?
총 3가지 방법이 존재합니다.
1. register로 파라미터들을 전달
2. 파라미터들을 block 또는 table에 저장해 두고, register에 block의 주소를 전달
3. 스택(Stack) 영역에 파라미터 값들을 push 하고, pop 하여 파라미터 값들을 전달
1번째 방식은 파라미터 개수가 5개보다 작거나 같을 경우 사용되고, 2,3번째 Block 또는 Stack을 사용한 방식은 파라미터 개수에 제한되지 않는다는 장점이 존재합니다.
System Services
운영체제는 다양한 시스템 서비스들을 제공합니다. 시스템 서비스들은 프로그램 개발 및 실행에 편리한 환경을 제공해 줍니다. 서비스 종류는 아래와 같이 구성되어 있습니다.
File manipulation : 파일 및 디렉터리를 생성, 삭제, 수정, 목록 등 수행
Status information : 날짜, 시간, 사용할 수 있는 메모리 크기, 디스크 크기, 유저 수 등의 정보를 제공
Programming language support : 컴파일러, 어셈블리어, 디버거, 인터프리터 등 제공
Program loading and execution : Loader 및 상위 레벨 및 기계어를 위한 디버깅 시스템 제공
Communications : 프로세스, 유저, 혹은 다른 호스트 간에 Virtual Connection 생성을 위한 메커니즘 제공
Background services : 부팅 관련, 프로세스 스케줄링, 에러 로깅, 출력 등 제공
Application programs : 명령어, 마우스 클릭 등 제공
Linkers and Loaders
사용자가 프로그램을 실행하였을 때 발생하는 현상과 소스 코드가 컴파일되어 프로그램이 생성되기까지의 과정을 살펴봅시다.

프로그래머가 main.c 코드를 작성한 후 컴파일을 진행하게 되면, 모든 물리적 메모리 위치에 로드되도록 설계된 relocatable object file이 생성됩니다. 이후, linker는 여러 relocatable object file과 library들을 포함시켜 하나의 single binary 형태인 executable file을 생성합니다.
생성된 실행 파일을 실행하기 위해 ./main 명령을 수행하면, shell은 프로그램을 실행시키기 위해 fork() system call을 호출하여 새로운 프로세스를 생성하게 됩니다. 이후, shell은 실행 파일 명을 execve()에 인자로 넘기고 execve() system call로 loader를 발생시킵니다. loader는 새로 생성된 프로세스의 주소 공간을 사용하여 프로그램을 메모리에 로드합니다. 이때, 동적으로 라이브러리를 실행 파일에 연결시키게 됩니다.
라이브러리에는 동적 라이브러리(dynamic library)와 정적 라이브러리(static library)가 존재하는데, 일반적으로 컴파일을 시도하면, 동적으로 라이브러리를 연결하는 dynamic library를 사용하게 됩니다.
동적 라이브러리는 실행 파일에서 사용되지 않은 라이브러리가 연결(link)되거나 로드(load)되는 것을 방지한다는 이점이 존재합니다. 대신에, 런타임 중에 필요에 의해 연결(link)되거나 로드(load)됩니다. 이러한 과정을 거쳐 프로그램이 실행됩니다.
그럼, 위에서 언급된 object file과 executable file은 어떤 내용을 담고 있을까요?
object file과 executable file은 컴파일된 기계어 코드(machine code)와 심볼 테이블(symbol table)을 가집니다.
*symbol table : 함수(function)와 변수(variable)에 대한 메타데이터(metadata)를 포함하는 테이블
하지만, 모든 운영체제의 object file과 executable file 포맷이 동일한 것은 아닙니다. 각 운영체제마다 각자의 표준 포맷을 가집니다. Linux 운영체제의 경우, ELF(Executalbe Linkable Format)을 사용하고 있고, Windows 운영체제의 경우, PE(Portable Exectuable format)을 사용합니다.
그렇기에, Linux에서 컴파일된 실행 파일을 Windows에서 실행하려고 할 경우, 실행 포맷이 달라 실행되지 않는 것을 경험해 보셨을 수도 있습니다. 이러한 불편한 점을 개선하기 위해 Python, Ruby와 같은 Interprerter 언어들이 나오게 되었고 이러한 언어들은 다양한 운영체제에서 실행할 수 있습니다.
Operating System Structure
1. Monolithic Structure
Monolithic 구조는 운영체제 구조 중 가장 간단한 구조로 커널의 모든 기능을 하나의 정적 바이너리 파일(Static Binary File)에 넣고 단일 주소 공간(Single Address Space)에서 실행되는 특징을 가집니다.
 |
 Linux system structure |
UNIX 시스템 구조를 살펴보면 Kernel 부분이 Layer를 이루거나 Module로 구성되어있지 않고, 한 곳에 모든 기능이 포함되어 있는 것을 확인할 수 있습니다. 그러므로, UNIX 시스템은 Monolithic 구조를 따른다고 볼 수 있습니다.
Linux 시스템 구조 또한 Monolithic 구조를 따릅니다. 그 이유는 리눅스는 전체적으로 단일 주소 공간(Single Address Space)에서 커널 모드가 실행되기 때문입니다. 하지만, UNIX 시스템 구조와 다른 점은 Monolithic 구조에 런타임에서 커널 구조를 변경할 수 있는 Moduler Design이 추가되었다는 점입니다.
Monolithic 구조의 장점은 system call interface에 overhead가 매우 작고, 커널 내에서 통신이 빠르다는 점입니다. 반면, 구조자체가 단순하긴 하지만 구현이 어렵고 확장성이 낮으며 커널에 모든 기능이 포함되어 있어 커널 크기가 크고 관리가 어렵다는 단점을 가집니다.
2. Layered Approach
다음으로, Layered Approach 구조는 user interface에서 hardware까지 층을 여러 개로 나누어 구성합니다.
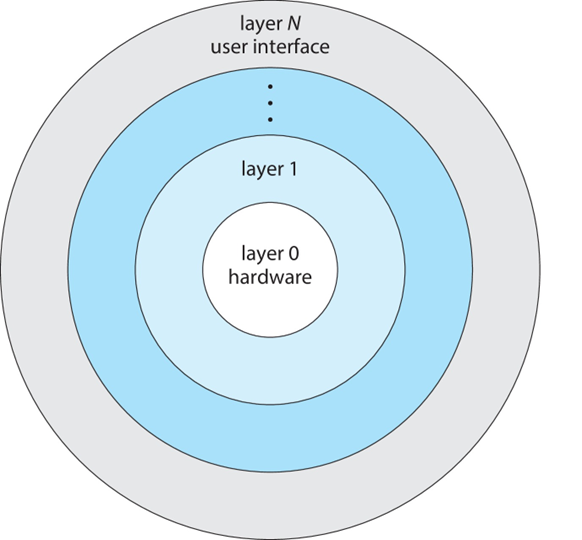
각 계층들은 각각 함수들을 사용하여 연결되어 있으며, 하위 계층에서 제공하는 작업으로만 구현됩니다. 또한 각 계층은 자신의 계층보다 하위에 있는 계층들이 어떤 연산을 하는지, 어떤 구조로 되어있는지 알 수 없도록 설계되어있습니다.
이러한 Layered approach는 구성과 디버깅이 단순하다는 장점 갖습니다. 특정 계층에서 버그가 발생했을 경우, 다른 계층과 연관성 없이 버그가 발생한 해당 계층만 디버깅을 수행하면 되기 때문입니다. 하지만, 여러 계층이 존재하다 보니 전체적인 성능이 낮아지는 단점이 존재합니다.
3. Microkernels
다음으로, Microkernel 구조는 커널이 커지고 관리가 어려운 Monolithic 구조에서 커널의 크기를 줄이고 관리가 쉽도록 구성되었습니다.

커널로부터 불필요한 것들을 제거하고 유저 프로그램들이 분리된 주소 공간에 거주하도록 설계해 놓은 구조입니다. Microkernel은 최소한의 프로세스와 메모리 관리와 통신 기능을 제공합니다.
주요 기능은 클라이언트 프로그램과 다양한 서비스들 간에 통신을 제공하는 것입니다. 하지만, 통신을 할 때 클라이언트 프로그램과 서비스 간에 직접 통신을 하지 않고 Microkernel과 메시지를 주고받아 간접적으로 통신합니다.
Microkernel은 쉽게 확장이 가능하며, 모든 새로운 서비스들이 유저 공간에서 추가되기 때문에 커널을 수정하지 않아도 되는 장점이 있습니다. 또한, 하드웨어에서 다른 하드웨어로 이식하기가 쉬우며, 대부분의 서비스가 유저 공간에서 실행되기 때문에 커널에 영향을 미치지 않고 높은 보안과 신뢰성을 가집니다.
반면에, 시스템 기능들이 많이 추가될 경우에는 오버헤드가 발생할 수 있다는 단점을 가집니다.
4. Modules
Modules은 커널이 핵심 구성요소들이 분리되어 있고 모듈들을 통해 추가적인 서비스들을 연결할 수 있도록 구성하였습니다. 즉, LKM(Loadable Kernel Modules)를 사용하여 운영 체제에서 실행 중인 커널을 확장하는 코드를 포함시킬 수 있게 하였습니다.
핵심 기능을 갖고 있고 확장이 가능하다는 점에서 Microkernel과 유사해 보일 수 있지만, Modules은 LKM으로 확장이 가능하기에 다른 서비스와 통신할 때 커널과 메시지를 주고받지 않아도 되기 때문에 더 효율적입니다.
5. Hybrid Systems
Hybrid Systems은 다른 구조들과 결합하여 새로운 구조를 만든 것입니다. 예를 들어, Linux와 같이 Monolithic 구조에 Modules을 추가하여 두 가지 구조를 동시에 가지는 것을 Hybrid Systems이라고 합니다.
현재 Linux와 Solaris 커널들은 Monolithic에 Modular를 추가하였으며, Windows 또한 주로 Monolithic 구조로 되어있으며, 다양한 하위 시스템 특성을 위한 Microkernel이 추가된 상태입니다.
애플의 MacOS와 iOS 또한 Hybrid System 구조를 사용하고 있고, Google의 Android 또한 Hybrid System 구조를 사용하고 있습니다. 그중 MacOS를 예시로 Hybrid System 구조를 알아봅시다.
 Architecture of Apple's macOS and iOS operating systems |
 The structure of Darwin |
대다수의 운영체제들은 하나의 system call interface를 사용하지만, Drawin은 두 개의 system call interface를 제공하는 것을 확인할 수 있습니다. Mach system calls과 BSD system calls을 사용하기 때문에 더 많은 종류의 라이브러리들을 사용할 수 있으며, device driver들을 개발을 위한 I/O Kit과 동적으로 모듈을 추가할 수 있는 ketxts(kernel extensions) 또한 제공합니다.
이와 같이, 각 운영체제들은 자신만의 구조를 갖추면서 추가로 다양한 기능을 사용자에게 제공하기 위해 모듈을 추가하거나 Microkernel을 추가하여 Hybrid system 방식을 활용하고 있다는 것을 알 수 있습니다.
Building and Booting an Operating System
어떻게 하드웨어가 커널이 어디에 있는지 알고 어떻게 커널이 로드되는지 알 수 있는지에 대해 다룹니다.
1. 컴퓨터의 전원이 켜지게 될 때, 비휘발성 펌웨어에 위치한 BIOS가 실행됩니다. 이후, BIOS는 Boot Block에 위치한 Boot Loader를 로드합니다.
2. Boot Loader는 필수적인 드라이버들(drivers)과 커널 모듈들을(kernel modules) 포함한 temporary RAM file system을 생성합니다. 커널이 올바르게 시동되기 위해 하드웨어 문제 점검, 손상된 파일 시스템 수정 등 필요한 모든 작업을 마무리하고 Kernel을 찾아 메모리에 로드시키고 Kernel이 실행됩니다.
3. 실행된 Kernel은 하드웨어를 초기화시키고, 루트 파일 시스템(root file system)을 마운트 하여 temporary RAM file system 위치에서 적절한 루트 파일 시스템 위치로 전환합니다. 이후, init 프로세스를 생성하고 init 프로세스가 다른 프로세스들을 생성하며 서비스들이 시작됩니다.
위와 같은 과정을 거쳐, 컴퓨터를 사용할 수 있게 되는 것입니다.
Operating-System Debugging
디버깅(Debugging)은 시스템에 에러를 발견하고 수정하는 활동을 의미합니다. 또한, 디버깅을 통해 병목현상을 처리함으로써 성능을 개선하기도 합니다.
예를 들어, 프로세스가 동작에 실패할 경우, 대부분의 운영체제는 에러 정보를 로그 파일에 기록합니다. 추가적으로, 운영체제는 Core Dump(프로세스의 메모리를 캡처 뜨는 행위)를 떠서 파일로 저장하여 분석할 수 있습니다.
이와 같이 시스템 성능을 개선하기 위해 시스템 성능을 모니터링하고 튜닝하도록 도와주는 여러 가지 도구들이 존재합니다. 접근 방식으로는 Counters와 Tracing이 있습니다.
Counters는 시스템 콜의 개수 또는 네트워크 장치 혹은 디스크에 수행되는 연산 개수 등을 카운트하여 시스템 활동을 추적합니다. 반면, Tracing은 시스템 콜 호출과 관련된 단계들과 같이 특정 이벤트에 대한 데이터를 수집합니다.
이렇게 운영체제는 유저에게 정말 다양하고 많은 서비스들을 제공하고 있습니다.
Operating System Structure에 대해 알아보았고 다음엔 Process에 대해 알아보겠습니다.
*참고 자료
https://www.geeksforgeeks.org/traps-and-system-calls-in-operating-system-os/
https://pages.cs.wisc.edu/~remzi/OSFEP/intro-syscall.pdf
'Computer Science > OperatingSystem' 카테고리의 다른 글
| [Operating System Concept] Processes - Chapter 3 (0) | 2023.07.23 |
|---|---|
| 디바이스 드라이버 (Device Driver) 개념 (0) | 2021.11.26 |
| 리눅스 디렉터리 구조와 명령어 정리 (0) | 2021.11.26 |
| 운영체제(OS) 역할 (0) | 2021.10.30 |


